KoboldCpp
KoboldCpp is a self-contained API for GGML and GGUF models.
This VRAM Calculator by Nyx will tell you approximately how much RAM/VRAM your model requires.
Nvidia GPU Quickstart
This guide assumes you're using Windows.
- Download the latest release: https://github.com/LostRuins/koboldcpp/releases
- Launch KoboldCpp. You may see a pop-up from Microsoft Defender, click
Run Anyway. - As of version 1.58, KoboldCpp should look like this:
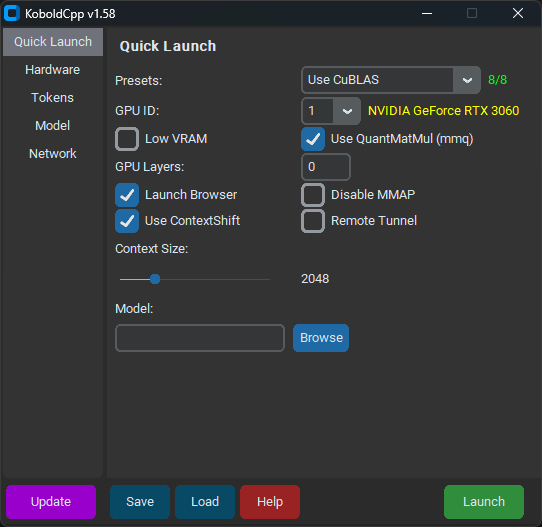
- Under the
Quick Launchtab, select the model and your preferredContext Size. - Select
Use CuBLASand make sure the yellow text next toGPU IDmatches your GPU. - Do not tick
Low VRAM, even if you have low VRAM. - Unless you have an Nvidia 10-series or older GPU, untick
Use QuantMatMul (mmq). GPU Layersshould have been populated when you loaded your model. Leave it there for now.- Under the
Hardwaretab, tickHigh Priority. - Click
Saveso you don't have to configure KoboldCpp on every launch. - Click
Launchand wait for the model to load.
You should see something like this:
Load Model OK: True
Embedded Kobold Lite loaded.
Starting Kobold API on port 5001 at http://localhost:5001/api/
Starting OpenAI Compatible API on port 5001 at http://localhost:5001/v1/
======
Please connect to custom endpoint at http://localhost:5001You can now connect to KoboldCpp within SillyTavern with http://localhost:5001 as the API URL and start chatting.
Congratulations! You're done!
Kind of.
GPU Layers
KoboldCpp is working, but you can improve performance by ensuring that as many layers as possible are offloaded to the GPU. You should see something like this in the terminal:
llm_load_tensors: offloading 9 repeating layers to GPU
llm_load_tensors: offloaded 9/33 layers to GPU
llm_load_tensors: CPU buffer size = 25215.88 MiB
llm_load_tensors: CUDA0 buffer size = 7043.34 MiB
....................................................................................................
llama_kv_cache_init: CUDA_Host KV buffer size = 1479.19 MiB
llama_kv_cache_init: CUDA0 KV buffer size = 578.81 MiBDon't be afraid of numbers; this part is easier than it looks. CPU buffer size refers to how much system RAM is being used. Ignore that. CUDA0 buffer size refers to how much GPU VRAM is being used. CUDA_Host KV buffer size and CUDA0 KV buffer size refer to how much GPU VRAM is being dedicated to your model's context. In this case, KoboldCpp is using about 9 GB of VRAM.
I have 12 GB of VRAM, and only 2 GB of VRAM is being used for context, so I have about 10 GB of VRAM left over to load the model. Because 9 layers used about 7 GB of VRAM and 7000 / 9 = 777.77 we can assume each layer uses approximately 777.77 MIB of VRAM. 10,000 MIB / 777.77 = 12.8, so I'll round down and load 12 layers with this model from now on.
Now do your own math using the model, context size, and VRAM for your system, and restart KoboldCpp:
- If you're smart, you clicked
Savebefore, and now you can load your previous configuration withLoad. Otherwise, select the same settings you chose before. - Change the
GPU Layersto your new, VRAM-optimized number (12 layers in my case). - Click
Saveto save your updated configuration.
You should now see something like this:
llm_load_tensors: offloading 12 repeating layers to GPU
llm_load_tensors: offloaded 12/33 layers to GPU
llm_load_tensors: CPU buffer size = 25215.88 MiB
llm_load_tensors: CUDA0 buffer size = 9391.12 MiB
....................................................................................................
llama_kv_cache_init: CUDA_Host KV buffer size = 1286.25 MiB
llama_kv_cache_init: CUDA0 KV buffer size = 771.75 MiBKoboldCpp is using about 11.5 GB of my 12 GB VRAM. This should perform a lot better than the settings generated automatically by KoboldCpp.
Congratulations! You're (actually) done!
For a more in-depth look at KoboldCpp settings, check out Kalomaze's Simple Llama + SillyTavern Setup Guide.