Summarize
What is it?
This extension allows you to create, store, and utilize automatically generated summaries based on the events happening in your chats. Summarization can help with outlining general details of what is happening in the story, which could be interpreted as a long-term memory, but take that statement with a grain of salt. Since the summaries are generated by language models, the outputs may lose some important details or contain hallucinations, so you're always advised to keep track of the summary state and correct it manually if needed.
Common configuration
The summarization extension is installed in SillyTavern by default, thus it will show up in ST's Extensions panel (stacked cubes icon) list like this:
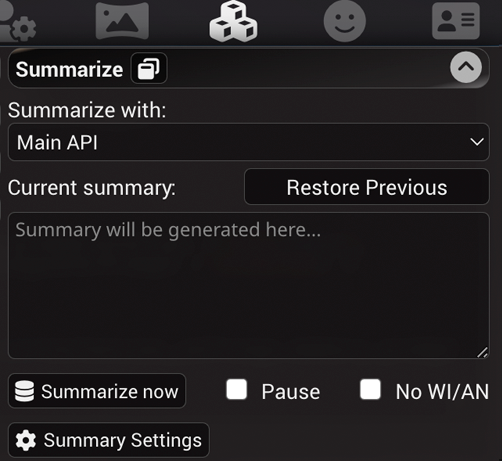
- Current summary - displays and provides an ability to modify the current summary. The summary is updated and embedded into the chat file's metadata for the message that was the last in context when the summary was generated. Deleting or editing a message from the chat that has a summary attached to it, will revert the state to the last valid summary.
- Restore Previous - removes the current summary, rolling it back to the previous state. This is useful if the summarizer does a poor job at any given point.
- Pause - check this to prevent the summary from being automatically updated. This is useful if you want to provide a custom summary of your own or to effectively disable the summary by clearing the box and stopping updates.
- Popup window - allows to detach the summary into a movable UI panel on the sidebar. Useful for the desktop layout to easily have access to summarization settings without having to navigate through the extensions menu.
- Injection Template - defines how the summary will be wrapped when being inserted into regular chat prompts. A special {{summary}} macro should be used to denote the exact location of the current summary state in the prompt injection text.
- Injection Position - sets the location of the prompt injection. The options are the same as for Author's Notes: before or after the main prompt, or in-chat at designated depth.
Supported summary sources
Main API
Summarization will be powered by your currently selected AI backend, model and settings. This method requires no additional setup, just a working API connection.
This option has the following sub-modes that differ depending on how the summary prompt is built:
- Raw, blocking. The summary will be generated using nothing but the summarization prompt and the chat history. Subsequent prompts will also include the previous summary with messages that were sent after the summary was generated (see example). This mode can (and will) generate prompts that have a lot of variability between them, so it is not recommended to use it with backends that have slow prompt processing times, such as llama.cpp and its derivatives.
- Raw, non-blocking. Same as above, but the chat generation will not be blocked during the summary generation. Not every backend supports simultaneous requests, so switch to blocking mode if summarization fails.
- Classic, blocking. The summarization prompt will be sent at the end of your usual generation prompt, as a neutral system instruction, not omitting the character card, main prompt, example dialogues and other parts of chat prompts. This usually results in prompts that play nicely with reusing processed prompts, so it is recommended to use with llama.cpp and its siblings.
Summary Settings explained
- Summary Prompt - defines the prompt that will used for creating a summary. May include any of the known macros, as well as a special {{words}} macro (see below).
- Target summary length (words) - defines the value of the {{words}} macro that can be inserted into the Summary Prompt. This setting is completely optional and has no effect at all if the macro is not used.
- API response length (tokens) - allows to set an override API response length for generating summaries that are different from the globally set value.
- Max messages per request (raw modes only) - set to limit the maximum number of messages that will be included in one summarization prompt.
0means no explicit limitation, but the resulting number of messages to summarize will still depend on the maximum context size, calculated using the formula:max summary buffer = context size - summarization prompt - previous summary - response length. Use this when you want to get more focused summaries on models with large context sizes. - No WI/AN - omit World Info and Author's Note from text to be summarized. Only has an effect when using the Classic prompt builder. The Raw prompt builder always omits WI/AN.
- Update every X messages - sets the interval at which the summary is generated.
0means that the automatic summarization is disabled, but you can still trigger it manually by clicking the "Summarize now" button. This should be adjusted based on how quickly the prompt buffer entirely fills with chat messages. Ideally, you'd want to have the first summary generated when the messages are starting to get dropped out of the prompt. - Update every X words - same as above, but using words (not tokens!) instead of messages, theoretically can be a more accurate measurement due to how unpredictable the contents of chat messages usually are, but your mileage may vary.
If both "Update every" sliders are set to a non-zero value, then both will trigger summary updates at their respective intervals, depending on what happens first. It is strongly advised to update these values accordingly when you switch to another model that has differing context sizes, otherwise, the summary generation may trigger too often, or never at all.
If you're unsure about the interval settings, you can click the "magic wand" button above the "Update every" sliders to try and guess the optimal values based on some simple heuristics. A brief description of the algorithm is as follows:
- Calculate token and word counts for all chat messages
- Determine target summary length based on desired prompt words
- Calculate the maximum number of messages that can fit in the prompt based on the average message length
- If "Max messages" is set, adjust the average to account for messages that don't fit the summary limit
- Round down the adjusted average messages per prompt to a multiple of 5
Example prompts
Raw prompt
System:
[Summarization prompt]
Previous summary.
User:
Message foo.
Char:
Message bar.Classic prompt
[Main prompt]
[Character card]
[Example dialogues]
User:
Message foo.
Char:
Message bar.
System:
[Summarization prompt]Extras API
Extras server with the summarize module could run an auxiliary summarization model (BART).
It has a very small context size (~1024 tokens), so its ability to handle large summaries is quite limited.
To configure the Extras summary source, do the following:
- Install or Update Extras to the latest version.
- Run Extras with the
summarizemodule enabled:python server.py --enable-modules=summarize
Changing Summary Model
By default, Summarize uses the Qiliang/bart-large-cnn-samsum-ChatGPT_v3 model for summarization purposes.
This can be changed by using the command line argument --summarization-model=(###Hugging-Face-Model-URL-Here###)
A known alternate Summarize model is Qiliang/bart-large-cnn-samsum-ElectrifAi_v10.