Image Generation
Use local or cloud-based Stable Diffusion, FLUX or DALL-E APIs to generate images.
Automatically generate images as replies to your messages for full immersion,
generate from chat history and character information from the wand menu or slash commands,
or use the /sd (anything_here) command in the chat input bar to make an image with your own prompt.
Most common Stable Diffusion generation settings are customizable within the SillyTavern UI.
- Supports
multiple image generation sources , both local and cloud-based - Various
generation modes for characters, scenes, and custom prompts Slash commands for easy image generation within chatsInteractive mode to trigger image generation based on natural language requests- Customizable prompt templates and
prefixes for consistent style and quality Character-specific prompt prefixes for tailored character imagesStyle presets to quickly switch between different image generation settings- Flexible
visibility options for generated images in chat - Advanced
ComfyUI integration for highly customizable workflows - Ability to
view all generated images in a character gallery Image swipes feature to regenerate images while keeping the same prompt- Options to
edit prompts before generation andextend free-mode prompts - Integration with AI
function calling for automatic image generation detection
Supported sources
Generation modes
How to generate an image
- Use the "Image Generation" item in the extensions context menu (wand).
- Type a
/sd (argument)slash command with an argument from the Generation modes table. Anything else would trigger a "free mode" to make SD generate whatever you prompted. Example:/sd apple treewould generate a picture of an apple tree. - Look for a paintbrush icon in the context actions for chat messages. This will force the "Raw Message" mode for the selected message.
Every generation mode besides raw message and free mode will trigger a prompt generation using your currently selected main generation API to convert chat context into the SD prompt. You can configure the instruction template for generating prompts for every generation mode using the "SD Prompt Templates" settings drawer in the extensions panel.
Tips and tricks for the /sd command usage
View all generated images
To view all saved images for a character (including other chats), open a gallery from a "More..." dropdown menu on a character info panel, or use a /show-gallery slash command.
Specify a negative prompt
Use a negative named argument before the prompt to enforce a specific negative prompt for this generation.
/sd negative="fries" cute tater farmer holding a tayto in a spud-fieldInclude a character-specific prefix
Use a special {{charPrefix}} macro in free-prompt mode to include positive and negative prompt prefixes (if defined) for the current character.
/sd {{charPrefix}}, riding a bikeSuppress a chat message
You can avoid posting a generated image into the chat by passing a quiet=true named argument. The image will still be added into the character gallery, and the command will produce a relative URL to the image that can be consumed by other commands.
The example below will send the generated image using Markdown as a user persona.
/sd quiet=true me | /send Here's a picture of me: Image swipes
Image swipes allow rerolling the image generation while keeping the same prompt. If a fixed seed is set, it will be randomized for the next generation. Image dimensions that were overridden via the /sd slash command are preserved for swiped images.
To cycle through images, hover a mouse cursor (tap on mobile) over a generated image to reveal arrow buttons and swipes counter. Tapping the right arrow on the latest image will generate a new one.
'Swipes' here is just a name, don't try the actual swiping gesture, as this will regenerate the message itself, not the attached image.
Options
Edit prompts before generation
This option lets you edit automatically generated prompts before they are sent to the Image Generation API. You can also edit or discard the saved negative prompt and override the resolution when regenerating an image that was originally created with the /sd command.
Use function tool
Uses function calling to automatically detect the intention to generate an image.
Requirements:
- Must have image generation configured with a supported source.
- Must use a supported Chat Completion API model and have function tool calling enabled in the AI Response settings.
- The "Use function tool" option must be enabled in the Image Generation settings.
- The user should express an intent to generate an image in the chat message, e.g. "Send me a picture of a cat".
The interactive mode will not trigger when the function tool is enabled.
Use interactive mode
Allows you to trigger an image generation instead of text as a reply to a user message that follows the special pattern:
- Contains one of the following verbs: send, mail, imagine, generate, make, create, draw, paint, render
- Followed by one of the following nouns (not further than 10 characters away): pic, picture, image, drawing, painting, photo, photograph
- Followed by a target subject of image generation, could be optionally preceded by phrases like "of a" or "of this".
Examples of valid requests and captured subjects:
Can you please send me a picture of a cat=>catGenerate a picture of the Eiffel tower=>Eiffel towerLet's draw a painting of Mona Lisa=>Mona Lisa
Some special subjects trigger a predefined generation mode:
- 'you, 'yourself' => "Yourself"
- 'your face', 'your portrait', 'your selfie' => "Your Face"
- 'me', 'myself' => "Me"
- 'story', 'scenario', 'whole story' => "The Whole Story"
- 'last message' => "The Last Message"
- 'background', 'scene background', 'scene', 'scenery', 'surroundings', 'environment' => "Background"
Extend free-mode prompts
When using the interactive mode of the slash command, automatically extend free-mode generation subject descriptions by prompting your main API.
Minimal prompt processing
When enabled, reduces the processing applied to prompts returned by the LLM for image generation. Only normalization and whitespace reduction are performed, skipping the aggressive sanitization that is done by default. This is useful when working with advanced workflows (e.g., ComfyUI) that accept structured prompt formats like JSON.
Snap auto-adjusted resolutions
Snap image generation requests with a forced aspect ratio (portraits, backgrounds) to the nearest known resolution, while trying to preserve the absolute pixel counts. Refer to the "Resolution" dropdown for the list of possible options.
Recommended for SDXL models.
Common prompt prefix
Pro Tip
Use {prompt} macro to specify where exactly the generated prompt will be inserted.
Added before every generated or free-mode prompt. Commonly used for setting the overall style of the picture.
Example: best quality, anime lineart.
Negative prompt
Characteristics of the image you don't want to be present in the output.
Example: bad quality, watermark.
Character-specific prompt prefix
Pro Tip
If supported by the generation source, you can also use LoRAs/embeddings here, for example: <lora:DonaldDuck:1>.
Any characteristics that describe the currently selected character. Will be added after a common prefix.
Example: female, green eyes, brown hair, pink shirt.
You can also specify a negative prompt prefix for any unwanted content. It will be combined with the general negative prompt.
Limitations:
- Works only in 1-to-1 chats. Will not be used in groups.
- Won't be used for backgrounds and free mode generations.
Note
To force include a character prefix into a free mode prompt, use the {{charPrefix}} macro anywhere in the prompt.
If you want to share the prefixes with others, tick the "Shareable" checkbox. This will save them with the character data, rather than your local settings.
Styles
Use this to quickly save and restore your favorite style/quality presets to use them later or when switching between models. The following is included in the Style preset:
- Common Prompt Prefix
- Negative Prompt
You can also switch between styles using the /imagine-style command (or /sd-style or /img-style).
Chat Message Visibility
Generated images inserted into the chat are hidden in the main API prompts by default, but this can be overriden individually per generation initiator ("Magic wand" icon, slash command, interactive mode). This can be used for making the experience more immersive by letting the characters "acknowledge" the images. Multimodal models in Chat Completions API may also 'see' the images if "Send inline images" is enabled.
A text message can be customized by changing the "Chat Message Template" under Image Prompt Templates. All regular macros can be used in this template, plus a special {{prompt}} macro to specify where the image prompt will be added.
ComfyUI Configuration
ComfyUI is a fast and very flexible option for image generation.
If you're familiar with ComfyUI, the tl;dr is: make your workflow in ComfyUI, download it in API format, and paste it into the SillyTavern ComfyUI Workflow Editor. ST will submit your workflow to ComfyUI's API and you will get an image in your chat. But with great power comes great responsibility, and the main responsibility is inserting placeholders in your workflow JSON so you can change settings from SillyTavern.
If you're not familiar with ComfyUI, you can still use it to generate images in SillyTavern using the default workflow. Later, when you want great power, you can learn how to use ComfyUI...
Controls
This panel allows you to configure and manage your ComfyUI integration with SillyTavern.
Server Type
- Standard Server is when you call ComfyUI directly whether on your local machine or hosted elsewhere.
- RunPod Serverless Endpoint is for running ComfyUI through RunPod's serverless API. Serverless can be a good option for remote generation as you can get the same control over workflows as a standard server but can take advantage of more powerful hosted GPUs and only be charged when you're actively generating images. The majority of the usage is the same. Differences from standard server setup and behavior is described
below .
Standard Server setup
Enter the URL of your ComfyUI server in the ComfyUI URL input field. The default value is http://127.0.0.1:8188.
If you are using SwarmUI, the default port for the
managed ComfyUI server is 7821,
20 ports higher than the default port for SwarmUI.
After entering the URL, choose Connect to validate and establish a connection. The ComfyUI server must be accessible from the SillyTavern host machine.
ComfyUI RunPod Setup
- You'll need a RunPod account and to add some money to it. You can probably expect around 2 cents per image for Qwen image generation on an RTX 4090 though YMMV. $5 in credits should last a while.
- https://console.runpod.io/hub/runpod-workers/worker-comfyui is a flux1 dev configuration that you can use to create your own serverless endpoint.
- There is information there on creating your own configuration if you want to use a different model or add LoRAs.
- Create an API key for access to the serverless endpoint: https://console.runpod.io/user/settings
- In ST, select ComfyUI as the Source and RunPod Serverless Endpoint as the Server Type.
- Set the ComfyUI RunPod URL to the URL of your endpoint.
- Set the API key.
- Click Connect. If the API key and URL are correct, you should get toasts indicating success.
- The ComfyUI workflow configuration flow is the same as local.
- Use the "Export (API)" option.
- Depending on your local setup, you may need to/want to pick a variation of the model for use on RunPod. For example, if you use a quantized GGUF locally, but want to use an fp16 version on RunPod. The JSON workflow you use in ST needs to have this change.
- Model, samplers, VAE, etc cannot be determined dynamically so your workflow needs to have these hard coded (no
%model%substitution). - Other substitutions should work the same as local.
Note
The serverless configuration does not currently embed the workflow into the output image. i.e., you won't be able to drag/drop the image into local ComfyUI to see the seed or prompt. This is just a limitation of the RunPod handler and is a capability that could be added on that side.
Workflow Management
Select a ComfyUI workflow from the dropdown menu. Two default workflows are provided:
- Default_Comfy_Workflow.json: A basic text-to-image workflow supporting the most common image generation settings.
- Char_Avatar_Comfy_Workflow.json: A sample image-to-image workflow that uses the character avatar, plus the prompt, to generate an image.
Use the following buttons to manage your workflows:
- Open workflow editor to view and modify the selected workflow.
- Create new workflow to create a new workflow with a custom name.
- Delete workflow to remove the selected workflow.
Workflow Editor
The ComfyUI Workflow Editor allows you to view and modify ComfyUI workflows for use with SillyTavern.
The main component of the editor is a large text area where you can insert or edit your ComfyUI workflow in JSON format.
To add a ComfyUI workflow to the editor, follow these steps:
- Enable 'Dev Mode' in ComfyUI settings.
- Use the 'Save (API Format)' option in ComfyUI to download the JSON data.
- Create a new workflow in SillyTavern and open the editor.
- Paste the downloaded JSON data into the text area.
- Replace specific values with placeholders as needed for your use case.
Tips
You can add the API-format JSON file directly to the data/default-user/user/workflows directory in your SillyTavern installation. This will save you from steps 3 and 4.
Retain the original JSON file. If you need to open the workflow again in ComfyUI to make changes, it is much more convenient to edit the original file than the one with all the placeholders.
Placeholders
The editor provides a list of predefined placeholders that can be used in your workflow JSON. These placeholders are replaced with dynamic values when the workflow is executed in SillyTavern.
Placeholders marked with ✅ are present in your workflow JSON. Placeholders marked with ❌ are not present in your workflow JSON. You can add these placeholders to your workflow JSON as needed. You do not need to add all the placeholders, only the ones that your workflow uses and you want to replace dynamically.
Prompts
The %prompt% and %negative_prompt% placeholders are used to insert the image generation prompts into the workflow. These contain the final prompts generated by SillyTavern, including the generated prompt for your chosen /sd mode, the common prompt prefix, negative prompt, and character-specific prompt prefix.
For example, you may have tested your workflow with a prompt like "forest elf" in ComfyUI. To use this workflow in SillyTavern, you can replace the "forest elf" prompt with the %prompt% placeholder:
{
"class_type": "CLIPTextEncode",
"inputs": {
"clip": ["4", 1],
"text": "%prompt%"
}
}{
"class_type": "CLIPTextEncode",
"inputs": {
"clip": ["4", 1],
"text": "forest elf"
}
}Notice that the placeholder is wrapped in double quotes. This is important for the JSON format, and required by SillyTavern's placeholder replacement system. Even for numbers, you must use double quotes in the template JSON.
Sometimes the prompt (or other value) doesn't appear where you might expect. ComfyUI will remove nodes from the API version of the workflow if they are not necessary for the workflow to function in API mode.
For instance, this workflow uses a LoRA tag loader node with a prompt primitive so the workflow is clearer in UI mode:
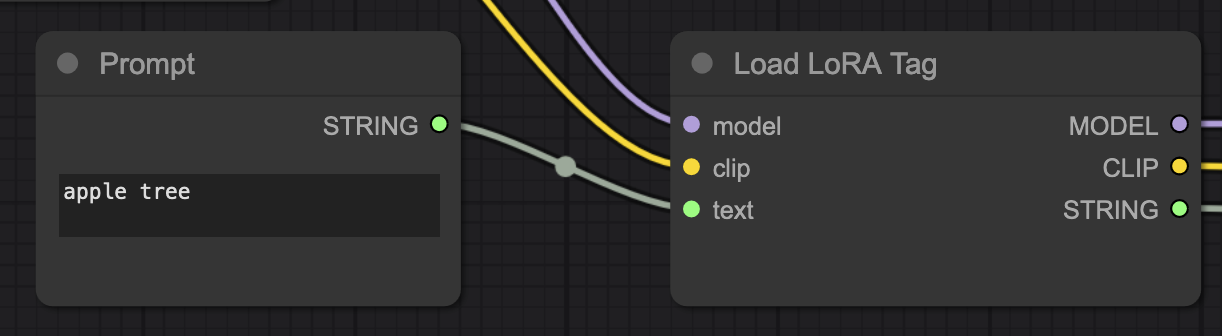
The prompt primitive node will be removed from the API version of the workflow, so you insert the placeholder in the LoraTagLoader node. Find the text "apple tree" in the workflow and replace it with the %prompt% placeholder:
{
"inputs": {
"text": "%prompt%",
"model": ["112", 0],
"clip": ["112", 1]
},
"class_type": "LoraTagLoader",
"_meta": {"title": "Load LoRA Tag"}
}{
"inputs": {
"text": "apple tree",
"model": ["112", 0],
"clip": ["112", 1]
},
"class_type": "LoraTagLoader",
"_meta": {"title": "Load LoRA Tag"}
}In some cases you may need to make several replacements in the workflow JSON, even if the prompt appears only once in the UI.
Model
The %model% placeholder will insert the value of the selected model in the image generation settings.
An example from the default text-to-image workflow:
{
"class_type": "CheckpointLoaderSimple",
"inputs": {
"ckpt_name": "%model%"
}
}{
"class_type": "CheckpointLoaderSimple",
"inputs": {
"ckpt_name": "sd15.safetensors"
}
}To load GGUF-quantized UNets, use a UNet Loader (GGUF) node in your workflow,
choose a GGUF model in the SillyTavern model dropdown, and use the %model% placeholder in the node's settings like this:
{
"inputs": {
"unet_name": "%model%"
},
"class_type": "UnetLoaderGGUF",
"_meta": {
"title": "Unet Loader (GGUF)"
}
}{
"inputs": {
"unet_name": "flux1-dev-Q4_0.gguf"
},
"class_type": "UnetLoaderGGUF",
"_meta": {
"title": "Unet Loader (GGUF)"
}
}If you have model types other than the usual SD checkpoints in ComfyUI
Stable Diffusion checkpoints, SD UNets, and GGUF-quantized UNets all appear in the Model dropdown. Models of one type will not work with workflows/loader nodes expecting another type. If you choose an incompatible model type in ST, ComfyUI will report a problem with the loader node.
Avatar images
Use the %user_avatar% and %char_avatar% placeholders to include the user and character avatars in the workflow. These placeholders are replaced with the PNG data of the avatars when the workflow is executed. The image data is encoded in base64 format, so you must decode it in your workflow. A popular choice for this task is the Load image (Base64) node.
In this example, the character avatar is loaded with a Load Image (Base64) node. It also uses an Image Resize node to rescale the image to whatever size is specified in the image generation settings:
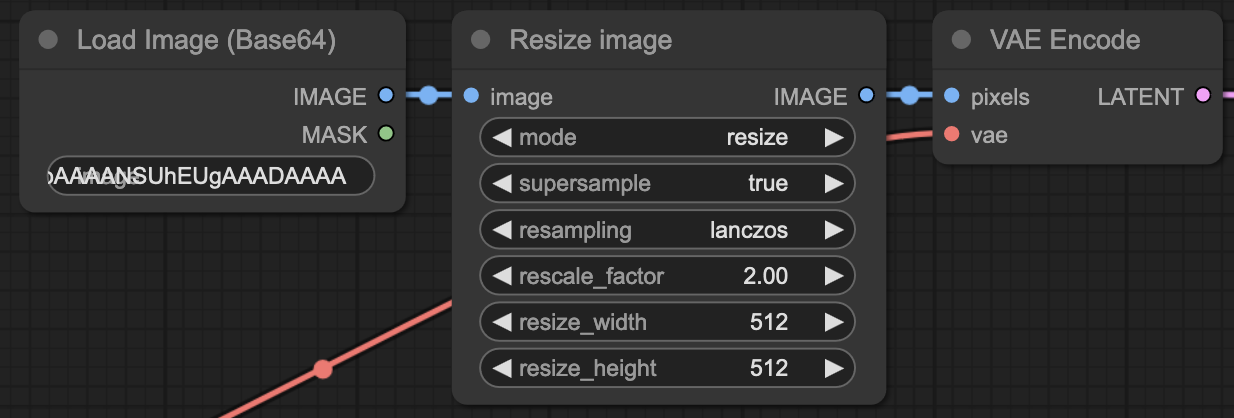
Insert the %char_avatar%, %width%, and %height% placeholders into the JSON for the Load Image (Base64) and Image Resize nodes:
{
"97": {
"inputs": {
"image": "%char_avatar%"
},
"class_type": "ETN_LoadImageBase64",
"_meta": {"title": "Load Image (Base64)"}
},
"98": {
"inputs": {
"mode": "resize",
"resize_width": "%width%",
"resize_height": "%height%",
"image": ["97", 0]
},
"class_type": "Image Resize",
"_meta": {"title": "Resize image"}
}
}To get a base64-encoded image string for testing your workflow in ComfyUI, use any online tool that converts images to base64 strings. Here's an example string you can use for initial testing: sd-comfy-base64-test-string.txt.
Other placeholders
Most other placeholders use the values of the corresponding controls in image generation settings, or the values that you specify with the /sd command:
%vae%, but most SD models include a VAE so the default workflows do not use this placeholder. Use it with custom workflows to load a VAE alongside a UNet, override the default VAE, etc.%sampler%%scheduler%%steps%%scale%%width%%height%%denoise%: for the sample image-to-image workflow, vary the denoise amount between about 0.5 (barely-noticeable changes to the source image) and 1.0 (a completely different image as if no source image was used). Not used by the default text-to-image workflow because there's no point using a value other than 1.0 for text-to-image.%clip_skip%: not used by the default workflows but available for custom workflows.
The %seed% placeholder will insert the seed value from the control if you have specified one. If you set the seed to -1, SillyTavern will generate a new random seed for each image in %seed%.
Custom placeholders
You can add custom placeholders to your workflow:
- Look for the "Custom" section below the predefined placeholders.
- Click the "+" button to add a new custom placeholder.
- Enter a name for the placeholder in the
findfield. - Enter the value that you want to replace the placeholder with in the
replacefield.
Custom placeholders will appear in a separate list below the predefined ones.
For example, you could replace the "SillyTavern" prefix for saved image filenames in the default workflow with a custom placeholder. Add a new custom placeholder with find set to filename_prefix and replace set to ServiceTensor. Insert the new %filename_prefix% placeholder into your workflow JSON. Now you can change the filename prefix from SillyTavern to ServiceTensor by changing the value of the custom placeholder.
{
"class_type": "SaveImage",
"inputs": {
"filename_prefix": "%filename_prefix%",
"images": ["8", 0]
}
}{
"class_type": "SaveImage",
"inputs": {
"filename_prefix": "SillyTavern",
"images": ["8", 0]
}
}Comfy tricks
Read all the general information on this page so you're familiar with the image generation options. Options such as switchable styles and common prompt prefixes, when combined with the total flexibility of ComfyUI workflows, allow you to create a wide variety of image generation setups.
Loading LoRAs
Use a LoRA tag loader node (such as Load LoRA Tag) to load any LoRAs specified in the prompt.
Now you can add as many LoRAs as you like to your prompt with tags like <lora:CroissantStyle:0.8>, and they will be loaded into your workflow.
This will also make the "pro-tip" of using LoRAs in
Setting workflow values from styles or slash-commands
You can use macros in custom placeholder values. As a practical example, let's say you sometimes want to generate images without a background, and you'd like this to be switchable with a slash-command or image style. Here's how you could do it:
- Make a ComfyUI workflow that removes the image background, or not, depending on the value of an input
- Use a custom placeholder to set the value of that input, but use
{{getvar::remove_background}}as the replace value - Now you can set the value of
remove_backgroundwith/setvar key=remove_background trueor/setvar key=remove_background falsebefore generating an image - The workflow will use the value you set to determine whether to remove the background
- Make an image style "No background" with common prompt prefix
{{setvar::remove_background::true}} - Use the style control or
/imagine-style No backgroundto set the value ofremove_backgroundtotruebefore generating an image